错误处理与文件操作
错误处理与文件操作
错误处理
error 接口
在实际工程项目中,我们希望通过程序的错误信息快速定位问题,但是又不喜欢错误处理代码写得冗余而又啰嗦。Go 语言没有提供像 Java、C# 语言中的 try...catch 异常处理方式,而是通过函数返回值逐层往上抛。这种设计,鼓励工程师在代码中显式地检查错误,而非忽略错误,好处就是避免漏掉本应处理的错误。
什么是错误:
错误指的是可能出现问题的地方出现了问题,比如打开一个文件时失败,这种情况在人们的意料之中。
而异常指的是不应该出现问题的地方出现了问题,比如引用了空指针,这种情况在人们的意料之外。可见,错误是业务过程的一部分,而异常不是。
Go 中的错误也是一种类型。错误用内置的 error 类型表示,就像其他类型如 int、float64 一样。错误值可以存储在变量中,从函数中返回等。
错误处理示例:
package main
import (
"fmt"
"os"
)
func main() {
f, err := os.Open("/test.txt")
if err != nil {
fmt.Println(err)
return
}
// 根据f进行文件的读或写
fmt.Println(f.Name(), "opened successfully")
}在 os 包中有打开文件的功能函数:func Open(name string) (file *File, err error)。如果文件已经成功打开,那么 Open 函数将返回文件处理。如果在打开文件时出现错误,将返回一个非 nil 错误。
如果一个函数或方法返回一个错误,那么按照惯例,它必须是函数返回的最后一个值。因此,Open 函数返回的值中,err 是最后一个值。
处理错误的惯用方法是将返回的错误与 nil 进行比较。nil 值表示没有发生错误,而非 nil 值表示出现错误。
错误类型表示:
Go 语言通过内置的错误接口提供了非常简单的错误处理机制:
type error interface {
Error() string
}它包含一个带有 Error() string 的方法。任何实现这个接口的类型都可以作为一个错误使用。这个方法提供了对错误的描述。
当打印错误时,fmt.Println 函数在内部调用 Error() 方法来获取错误的描述。
从错误中提取更多信息的三种方法:
方法一:断言底层结构类型并从结构字段获取更多信息
如果仔细阅读 Open 函数的文档,可以看到它返回的是 PathError 类型的错误。PathError 是一个 struct 类型:
type PathError struct {
Op string
Path string
Err error
}
func (e *PathError) Error() string { return e.Op + " " + e.Path + ": " + e.Err.Error() }PathError 通过声明 Error() string 方法实现了错误接口。Path 字段包含导致错误的文件的路径:
package main
import (
"fmt"
"os"
)
func main() {
f, err := os.Open("/test.txt")
if err, ok := err.(*os.PathError); ok {
fmt.Println("File at path", err.Path, "failed to open")
return
}
fmt.Println(f.Name(), "opened successfully")
}方法二:断言底层结构类型,并调用方法获取更多信息
比如 DNSError 结构有两个方法 Timeout() bool 和 Temporary() bool:
type DNSError struct {
...
}
func (e *DNSError) Error() string {
...
}
func (e *DNSError) Timeout() bool {
...
}
func (e *DNSError) Temporary() bool {
...
}示例代码:
package main
import (
"fmt"
"net"
)
func main() {
addr, err := net.LookupHost("golangbot123.com")
if err, ok := err.(*net.DNSError); ok {
if err.Timeout() {
fmt.Println("operation timed out")
} else if err.Temporary() {
fmt.Println("temporary error")
} else {
fmt.Println("generic error: ", err)
}
return
}
fmt.Println(addr)
}方法三:直接比较
filepath 包的 Glob 函数用于返回与模式匹配的所有文件的名称。当模式出现错误时,该函数将返回一个错误 ErrBadPattern:
var ErrBadPattern = errors.New("syntax error in pattern")errors.New() 用于创建新的错误。当模式出现错误时,由 Glob 函数返回 ErrBadPattern:
package main
import (
"fmt"
"path/filepath"
)
func main() {
files, error := filepath.Glob("[")
if error != nil && error == filepath.ErrBadPattern {
fmt.Println(error)
return
}
fmt.Println("matched files", files)
}不要忽略错误:永远不要忽略一个错误。忽视错误会招致麻烦。使用空白标识符
_忽略错误会使输出看起来正常,但实际上可能是错误的。所以不要忽略错误。
自定义错误
创建自定义错误可以使用 errors 包下的 New() 函数,以及 fmt 包下的 Errorf() 函数:
// errors包:
func New(text string) error {}
// fmt包:
func Errorf(format string, a ...interface{}) error {}errors.New() 的实现原理:
package errors
func New(text string) error {
return &errorString{text}
}
type errorString struct {
s string
}
func (e *errorString) Error() string {
return e.s
}使用 errors.New() 创建自定义错误:
package main
import (
"errors"
"fmt"
"math"
)
func circleArea(radius float64) (float64, error) {
if radius < 0 {
return 0, errors.New("Area calculation failed, radius is less than zero")
}
return math.Pi * radius * radius, nil
}
func main() {
radius := -20.0
area, err := circleArea(radius)
if err != nil {
fmt.Println(err)
return
}
fmt.Printf("Area of circle %0.2f", area)
}使用 fmt.Errorf() 添加更多信息:
package main
import (
"fmt"
"math"
)
func circleArea(radius float64) (float64, error) {
if radius < 0 {
return 0, fmt.Errorf("Area calculation failed, radius %0.2f is less than zero", radius)
}
return math.Pi * radius * radius, nil
}
func main() {
radius := -20.0
area, err := circleArea(radius)
if err != nil {
fmt.Println(err)
return
}
fmt.Printf("Area of circle %0.2f", area)
}使用 struct 类型和字段提供更多错误信息:
第一步是创建一个 struct 类型来表示错误,命名约定:名称应以 Error 结尾:
type areaError struct {
err string
radius float64
}第二步,实现 error 接口:
func (e *areaError) Error() string {
return fmt.Sprintf("radius %0.2f: %s", e.radius, e.err)
}完整示例:
package main
import (
"fmt"
"math"
)
type areaError struct {
err string
radius float64
}
func (e *areaError) Error() string {
return fmt.Sprintf("radius %0.2f: %s", e.radius, e.err)
}
func circleArea(radius float64) (float64, error) {
if radius < 0 {
return 0, &areaError{"radius is negative", radius}
}
return math.Pi * radius * radius, nil
}
func main() {
radius := -20.0
area, err := circleArea(radius)
if err != nil {
if err, ok := err.(*areaError); ok {
fmt.Printf("Radius %0.2f is less than zero", err.radius)
return
}
fmt.Println(err)
return
}
fmt.Printf("Area of circle %0.2f", area)
}使用结构类型的方法提供更多错误信息:
计算矩形面积的例子,当长度或宽度小于 0 时输出错误:
type areaError struct {
err string // error description
length float64 // length which caused the error
width float64 // width which caused the error
}
func (e *areaError) Error() string {
return e.err
}
func (e *areaError) lengthNegative() bool {
return e.length < 0
}
func (e *areaError) widthNegative() bool {
return e.width < 0
}
func rectArea(length, width float64) (float64, error) {
err := ""
if length < 0 {
err += "length is less than zero"
}
if width < 0 {
if err == "" {
err = "width is less than zero"
} else {
err += ", width is less than zero"
}
}
if err != "" {
return 0, &areaError{err, length, width}
}
return length * width, nil
}
func main() {
length, width := -5.0, -9.0
area, err := rectArea(length, width)
if err != nil {
if err, ok := err.(*areaError); ok {
if err.lengthNegative() {
fmt.Printf("error: length %0.2f is less than zero\n", err.length)
}
if err.widthNegative() {
fmt.Printf("error: width %0.2f is less than zero\n", err.width)
}
}
fmt.Println(err)
return
}
fmt.Println("area of rect", area)
}panic 和 recover
Golang 中引入两个内置函数 panic 和 recover 来触发和终止异常处理流程,同时引入关键字 defer 来延迟执行 defer 后面的函数。一直等到包含 defer 语句的函数执行完毕时,延迟函数(defer 后的函数)才会被执行,而不管包含 defer 语句的函数是通过 return 的正常结束,还是由于 panic 导致的异常结束。可以在一个函数中执行多条 defer 语句,它们的执行顺序与声明顺序相反。
当程序运行时,如果遇到引用空指针、下标越界或显式调用 panic 函数等情况,则先触发 panic 函数的执行,然后调用延迟函数。调用者继续传递 panic,因此该过程一直在调用栈中重复发生:函数停止执行,调用延迟执行函数等。如果一路在延迟函数中没有 recover 函数的调用,则会到达该协程的起点,该协程结束,然后终止其他所有协程,包括主协程(类似于 C 语言中的主线程,该协程 ID 为 1)。
panic:
- 内建函数
- 假如函数 F 中书写了 panic 语句,会终止其后要执行的代码,在 panic 所在函数 F 内如果存在要执行的 defer 函数列表,按照 defer 的逆序执行
- 返回函数 F 的调用者 G,在 G 中,调用函数 F 语句之后的代码不会执行,假如函数 G 中存在要执行的 defer 函数列表,按照 defer 的逆序执行(这里的 defer 有点类似 try-catch-finally 中的 finally)
- 直到 goroutine 整个退出,并报告错误
recover:
- 内建函数
- 用来控制一个 goroutine 的 panicking 行为,捕获 panic,从而影响应用的行为
- 一般的调用建议:在 defer 函数中,通过 recover 来终止一个 goroutine 的 panicking 过程,从而恢复正常代码的执行;可以获取通过 panic 传递的 error
简单来讲:Go 中可以抛出一个 panic 的异常,然后在 defer 中通过 recover 捕获这个异常,然后正常处理。
defer / panic / recover 对比:
| 关键字 | 作用 | 执行时机 | 使用场景 |
|---|---|---|---|
defer | 延迟执行 | 函数返回前(无论正常 return 还是 panic) | 资源释放、文件关闭、锁释放 |
panic | 触发异常 | 立即终止当前函数执行 | 不可恢复的严重错误、逻辑上不可能到达的分支 |
recover | 捕获异常 | 仅在 defer 函数中有效 | 恢复 panic,防止程序崩溃,将异常转为 error |
错误与异常的转换:
错误和异常从 Golang 机制上讲,就是 error 和 panic 的区别。Golang 错误和异常是可以互相转换的:
- 错误转异常:比如程序逻辑上尝试请求某个 URL,最多尝试三次,尝试三次的过程中请求失败是错误,尝试完第三次还不成功的话,失败就被提升为异常了。
- 异常转错误:比如 panic 触发的异常被 recover 恢复后,将返回值中 error 类型的变量进行赋值,以便上层函数继续走错误处理流程。
异常处理的作用域(场景):
以下场景应使用异常(panic)表达:
- 空指针引用
- 下标越界
- 除数为 0
- 不应该出现的分支,比如 default
- 输入不应该引起函数错误
其他场景使用错误处理,这使得函数接口很精炼。对于异常,可以选择在一个合适的上游去 recover,并打印堆栈信息,使得部署后的程序不会终止。
错误处理的正确姿势
姿势一:失败的原因只有一个时,不使用 error
// 重构前
func (self *AgentContext) CheckHostType(host_type string) error {
switch host_type {
case "virtual_machine":
return nil
case "bare_metal":
return nil
}
return errors.New("CheckHostType ERROR:" + host_type)
}
// 重构后
func (self *AgentContext) IsValidHostType(hostType string) bool {
return hostType == "virtual_machine" || hostType == "bare_metal"
}说明:大多数情况,导致失败的原因不止一种,尤其是对 I/O 操作而言,用户需要了解更多的错误信息,这时的返回值类型不再是简单的 bool,而是 error。
姿势二:没有失败时,不使用 error
// 重构前
func (self *CniParam) setTenantId() error {
self.TenantId = self.PodNs
return nil
}
// 重构后
func (self *CniParam) setTenantId() {
self.TenantId = self.PodNs
}姿势三:error 应放在返回值类型列表的最后
resp, err := http.Get(url)
if err != nil {
return nil, err
}
value, ok := cache.Lookup(key)
if !ok {
// ...cache[key] does not exist…
}姿势四:错误值统一定义,而不是跟着感觉走
在每个包中增加一个错误对象定义文件,统一定义错误值:
var ERR_EOF = errors.New("EOF")
var ERR_CLOSED_PIPE = errors.New("io: read/write on closed pipe")
var ERR_NO_PROGRESS = errors.New("multiple Read calls return no data or error")
var ERR_SHORT_BUFFER = errors.New("short buffer")
var ERR_SHORT_WRITE = errors.New("short write")
var ERR_UNEXPECTED_EOF = errors.New("unexpected EOF")姿势五:错误逐层传递时,层层都加日志
层层都加日志非常方便故障定位。
姿势六:错误处理使用 defer
当 Golang 的代码执行时,如果遇到 defer 的闭包调用,则压入堆栈。当函数返回时,会按照后进先出的顺序调用闭包。对于闭包的参数是值传递,而对于外部变量却是引用传递,所以闭包中的外部变量 err 的值就变成外部函数返回时最新的 err 值。
func deferDemo() error {
err := createResource1()
if err != nil {
return ERR_CREATE_RESOURCE1_FAILED
}
defer func() {
if err != nil {
destroyResource1()
}
}()
err = createResource2()
if err != nil {
return ERR_CREATE_RESOURCE2_FAILED
}
defer func() {
if err != nil {
destroyResource2()
}
}()
err = createResource3()
if err != nil {
return ERR_CREATE_RESOURCE3_FAILED
}
defer func() {
if err != nil {
destroyResource3()
}
}()
err = createResource4()
if err != nil {
return ERR_CREATE_RESOURCE4_FAILED
}
return nil
}姿势七:当尝试几次可以避免失败时,不要立即返回错误
如果错误的发生是偶然性的,或由不可预知的问题导致。明智的选择是重新尝试失败的操作,有时第二次或第三次尝试时会成功。在重试时,需要限制重试的时间间隔或重试的次数,防止无限制的重试。
姿势八:当上层函数不关心错误时,建议不返回 error
对于一些资源清理相关的函数(destroy/delete/clear),如果子函数出错,打印日志即可,而无需将错误进一步反馈到上层函数,因为一般情况下,上层函数是不关心执行结果的,或者即使关心也无能为力,于是建议将相关函数设计为不返回 error。
姿势九:当发生错误时,不忽略有用的返回值
通常,当函数返回 non-nil 的 error 时,其他的返回值是未定义的,这些未定义的返回值应该被忽略。然而,有少部分函数在发生错误时,仍然会返回一些有用的返回值。比如,当读取文件发生错误时,Read 函数会返回可以读取的字节数以及错误信息。对于这种情况,应该将读取到的字符串和错误信息一起打印出来。
异常处理的正确姿势
姿势一:在程序开发阶段,坚持速错
速错,简单来讲就是"让它挂",只有挂了你才会第一时间知道错误。在早期开发以及任何发布阶段之前,最简单的同时也可能是最好的方法是调用 panic 函数来中断程序的执行以强制发生错误,使得该错误不会被忽略,因而能够被尽快修复。
姿势二:在程序部署后,应恢复异常避免程序终止
在 Golang 中,某个 Goroutine 如果 panic 了,并且没有 recover,那么整个 Golang 进程就会异常退出。所以,一旦 Golang 程序部署后,在任何情况下发生的异常都不应该导致程序异常退出,我们在上层函数中加一个延迟执行的 recover 调用来达到这个目的。
在调用 recover 的延迟函数中以最合理的方式响应该异常:
- 打印堆栈的异常调用信息和关键的业务信息,以便这些问题保留可见;
- 将异常转换为错误,以便调用者让程序恢复到健康状态并继续安全运行。
示例——panic 异常处理机制不会自动将错误信息传递给 error,所以要显式传递:
func funcA() (err error) {
defer func() {
if p := recover(); p != nil {
fmt.Println("panic recover! p:", p)
str, ok := p.(string)
if ok {
err = errors.New(str)
} else {
err = errors.New("panic")
}
debug.PrintStack()
}
}()
return funcB()
}姿势三:对于不应该出现的分支,使用异常处理
当某些不应该发生的场景发生时,就应该调用 panic 函数来触发异常:
switch s := suit(drawCard()); s {
case "Spades":
// ...
case "Hearts":
// ...
case "Diamonds":
// ...
case "Clubs":
// ...
default:
panic(fmt.Sprintf("invalid suit %v", s))
}姿势四:针对入参不应该有问题的函数,使用 panic 设计
入参不应该有问题一般指的是硬编码。对于同时支持用户输入场景和硬编码场景的情况,一般支持硬编码场景的函数是对支持用户输入场景函数的包装:
func MustCompile(str string) *Regexp {
regexp, error := Compile(str)
if error != nil {
panic(`regexp: Compile(` + quote(str) + `): ` + error.Error())
}
return regexp
}对于只支持硬编码单一场景的情况,函数设计时直接使用 panic,即返回值类型列表中不会有 error,这使得函数的调用处理非常方便。
文件操作
文件信息与权限
file 类在 os 包中,封装了底层的文件描述符和相关信息,同时封装了 Read 和 Write 的实现。
FileInfo 接口:
FileInfo 接口中定义了 File 信息相关的方法:
type FileInfo interface {
Name() string // base name of the file 文件名.扩展名 aa.txt
Size() int64 // 文件大小,字节数 12540
Mode() FileMode // 文件权限 -rw-rw-rw-
ModTime() time.Time // 修改时间 2018-04-13 16:30:53 +0800 CST
IsDir() bool // 是否文件夹
Sys() interface{} // 基础数据源接口(can return nil)
}权限控制:
Linux 下有 2 种文件权限表示方式,即"符号表示"和"八进制表示"。
(1)符号表示方式:
- --- --- ---
type owner group others文件的权限是这样子分配的:读 写 可执行 分别对应的是 r w x,如果没有哪一个权限,用 - 代替(- 文件 d 目录 | 连接符号)。例如:-rwxr-xr-x。
(2)八进制表示方式:
| 符号 | 八进制值 |
|---|---|
| r | 004 |
| w | 002 |
| x | 001 |
| - | 000 |
常用权限值:0755、0777、0555、0444、0666。
文件信息示例代码:
package main
import (
"os"
"fmt"
)
func main() {
/*
FileInfo:文件信息
interface
Name(),文件名
Size(),文件大小,字节为单位
IsDir(),是否是目录
ModTime(),修改时间
Mode(),权限
*/
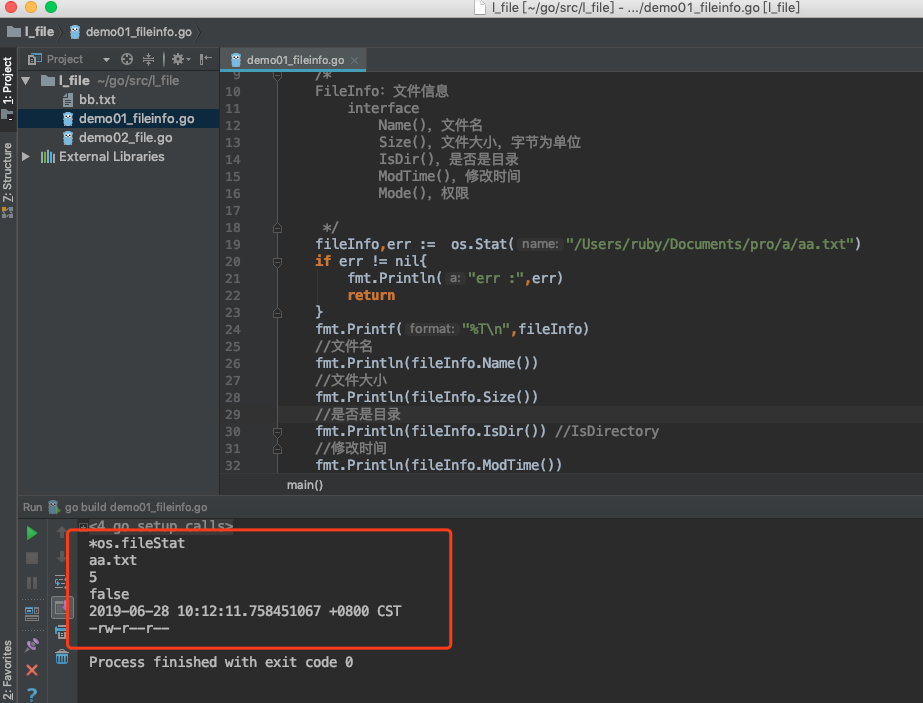
fileInfo, err := os.Stat("/Users/ruby/Documents/pro/a/aa.txt")
if err != nil {
fmt.Println("err :", err)
return
}
fmt.Printf("%T\n", fileInfo)
// 文件名
fmt.Println(fileInfo.Name())
// 文件大小
fmt.Println(fileInfo.Size())
// 是否是目录
fmt.Println(fileInfo.IsDir()) // IsDirectory
// 修改时间
fmt.Println(fileInfo.ModTime())
// 权限
fmt.Println(fileInfo.Mode()) // -rw-r--r--
}
文件创建、打开与关闭
打开模式:
const (
O_RDONLY int = syscall.O_RDONLY // 只读模式打开文件
O_WRONLY int = syscall.O_WRONLY // 只写模式打开文件
O_RDWR int = syscall.O_RDWR // 读写模式打开文件
O_APPEND int = syscall.O_APPEND // 写操作时将数据附加到文件尾部
O_CREATE int = syscall.O_CREAT // 如果不存在将创建一个新文件
O_EXCL int = syscall.O_EXCL // 和O_CREATE配合使用,文件必须不存在
O_SYNC int = syscall.O_SYNC // 打开文件用于同步I/O
O_TRUNC int = syscall.O_TRUNC // 如果可能,打开时清空文件
)File 结构主要函数:
type File // File代表一个打开的文件对象。
func Create(name string) (file *File, err error)
// Create采用模式0666(任何人都可读写,不可执行)创建一个名为name的文件,如果文件已存在会截断它(为空文件)。如果成功,返回的文件对象可用于I/O;对应的文件描述符具有O_RDWR模式。如果出错,错误底层类型是*PathError。
func Open(name string) (file *File, err error)
// Open打开一个文件用于读取。如果操作成功,返回的文件对象的方法可用于读取数据;对应的文件描述符具有O_RDONLY模式。如果出错,错误底层类型是*PathError。
func OpenFile(name string, flag int, perm FileMode) (file *File, err error)
// OpenFile是一个更一般性的文件打开函数,大多数调用者都应用Open或Create代替本函数。它会使用指定的选项(如O_RDONLY等)、指定的模式(如0666等)打开指定名称的文件。如果操作成功,返回的文件对象可用于I/O。如果出错,错误底层类型是*PathError。
func NewFile(fd uintptr, name string) *File
// NewFile使用给出的Unix文件描述符和名称创建一个文件。
func Pipe() (r *File, w *File, err error)
// Pipe返回一对关联的文件对象。从r的读取将返回写入w的数据。本函数会返回两个文件对象和可能的错误。
func (f *File) Name() string
// Name方法返回(提供给Open/Create等方法的)文件名称。
func (f *File) Stat() (fi FileInfo, err error)
// Stat返回描述文件f的FileInfo类型值。如果出错,错误底层类型是*PathError。
func (f *File) Fd() uintptr
// Fd返回与文件f对应的整数类型的Unix文件描述符。
func (f *File) Chdir() error
// Chdir将当前工作目录修改为f,f必须是一个目录。如果出错,错误底层类型是*PathError。
func (f *File) Chmod(mode FileMode) error
// Chmod修改文件的模式。如果出错,错误底层类型是*PathError。
func (f *File) Chown(uid, gid int) error
// Chown修改文件的用户ID和组ID。如果出错,错误底层类型是*PathError。
func (f *File) Close() error
// Close关闭文件f,使文件不能用于读写。它返回可能出现的错误。
func (f *File) Readdir(n int) (fi []FileInfo, err error)
// Readdir读取目录f的内容,返回一个有n个成员的[]FileInfo,这些FileInfo是被Lstat返回的,采用目录顺序。对本函数的下一次调用会返回上一次调用剩余未读取的内容的信息。如果n>0,Readdir函数会返回一个最多n个成员的切片。这时,如果Readdir返回一个空切片,它会返回一个非nil的错误说明原因。如果到达了目录f的结尾,返回值err会是io.EOF。如果n<=0,Readdir函数返回目录中剩余所有文件对象的FileInfo构成的切片。此时,如果Readdir调用成功(读取所有内容直到结尾),它会返回该切片和nil的错误值。如果在到达结尾前遇到错误,会返回之前成功读取的FileInfo构成的切片和该错误。
func (f *File) Readdirnames(n int) (names []string, err error)
// Readdir读取目录f的内容,返回一个有n个成员的[]string,切片成员为目录中文件对象的名字,采用目录顺序。对本函数的下一次调用会返回上一次调用剩余未读取的内容的信息。如果n>0,Readdir函数会返回一个最多n个成员的切片。这时,如果Readdir返回一个空切片,它会返回一个非nil的错误说明原因。如果到达了目录f的结尾,返回值err会是io.EOF。如果n<=0,Readdir函数返回目录中剩余所有文件对象的名字构成的切片。此时,如果Readdir调用成功(读取所有内容直到结尾),它会返回该切片和nil的错误值。如果在到达结尾前遇到错误,会返回之前成功读取的名字构成的切片和该错误。
func (f *File) Truncate(size int64) error
// Truncate改变文件的大小,它不会改变I/O的当前位置。如果截断文件,多出的部分就会被丢弃。如果出错,错误底层类型是*PathError。文件操作示例:
package main
import (
"fmt"
"path/filepath"
"path"
"os"
)
func main() {
/*
文件操作:
1.路径:
相对路径:relative
ab.txt
相对于当前工程
绝对路径:absolute
/Users/ruby/Documents/pro/a/aa.txt
.当前目录
..上一层
2.创建文件夹,如果文件夹存在,创建失败
os.MkDir(),创建一层
os.MkDirAll(),可以创建多层
3.创建文件,Create采用模式0666(任何人都可读写,不可执行)创建一个名为name的文件,如果文件已存在会截断它(为空文件)
os.Create(),创建文件
4.打开文件:让当前的程序,和指定的文件之间建立一个连接
os.Open(filename)
os.OpenFile(filename,mode,perm)
5.关闭文件:程序和文件之间的链接断开。
file.Close()
5.删除文件或目录:慎用,慎用,再慎用
os.Remove(),删除文件和空目录
os.RemoveAll(),删除所有
*/
// 1.路径
fileName1 := "/Users/ruby/Documents/pro/a/aa.txt"
fileName2 := "bb.txt"
fmt.Println(filepath.IsAbs(fileName1)) // true
fmt.Println(filepath.IsAbs(fileName2)) // false
fmt.Println(filepath.Abs(fileName1))
fmt.Println(filepath.Abs(fileName2)) // /Users/ruby/go/src/l_file/bb.txt
fmt.Println("获取父目录:", path.Join(fileName1, ".."))
// 2.创建目录
// err := os.Mkdir("/Users/ruby/Documents/pro/a/bb", os.ModePerm)
// if err != nil {
// fmt.Println("err:", err)
// return
// }
// fmt.Println("文件夹创建成功。。")
// err := os.MkdirAll("/Users/ruby/Documents/pro/a/cc/dd/ee", os.ModePerm)
// if err != nil {
// fmt.Println("err:", err)
// return
// }
// fmt.Println("多层文件夹创建成功")
// 3.创建文件:Create采用模式0666(任何人都可读写,不可执行)创建一个名为name的文件,如果文件已存在会截断它(为空文件)
// file1, err := os.Create("/Users/ruby/Documents/pro/a/ab.txt")
// if err != nil {
// fmt.Println("err:", err)
// return
// }
// fmt.Println(file1)
// file2, err := os.Create(fileName2) // 创建相对路径的文件,是以当前工程为参照的
// if err != nil {
// fmt.Println("err :", err)
// return
// }
// fmt.Println(file2)
// 4.打开文件:
// file3, err := os.Open(fileName1) // 只读的
// if err != nil {
// fmt.Println("err:", err)
// return
// }
// fmt.Println(file3)
/*
第一个参数:文件名称
第二个参数:文件的打开方式
const (
// Exactly one of O_RDONLY, O_WRONLY, or O_RDWR must be specified.
O_RDONLY int = syscall.O_RDONLY // open the file read-only.
O_WRONLY int = syscall.O_WRONLY // open the file write-only.
O_RDWR int = syscall.O_RDWR // open the file read-write.
// The remaining values may be or'ed in to control behavior.
O_APPEND int = syscall.O_APPEND // append data to the file when writing.
O_CREATE int = syscall.O_CREAT // create a new file if none exists.
O_EXCL int = syscall.O_EXCL // used with O_CREATE, file must not exist.
O_SYNC int = syscall.O_SYNC // open for synchronous I/O.
O_TRUNC int = syscall.O_TRUNC // truncate regular writable file when opened.
)
第三个参数:文件的权限:文件不存在创建文件,需要指定权限
*/
// file4, err := os.OpenFile(fileName1, os.O_RDONLY|os.O_WRONLY, os.ModePerm)
// if err != nil {
// fmt.Println("err:", err)
// return
// }
// fmt.Println(file4)
// 5.关闭文件,
// file4.Close()
// 6.删除文件或文件夹:
// 删除文件
// err := os.Remove("/Users/ruby/Documents/pro/a/aa.txt")
// if err != nil {
// fmt.Println("err:", err)
// return
// }
// fmt.Println("删除文件成功。。")
// 删除目录
err := os.RemoveAll("/Users/ruby/Documents/pro/a/cc")
if err != nil {
fmt.Println("err:", err)
return
}
fmt.Println("删除目录成功。。")
}I/O 接口
I/O 操作也叫输入输出操作。其中 I 是指 Input,O 是指 Output,用于读或者写数据的。Golang 标准库对 IO 的抽象非常精巧,各个组件可以随意组合,可以作为接口设计的典范。
io 包中提供 I/O 原始操作的一系列接口。主要包装了 os 包中的那些实现,并将这些抽象成为实用性的功能。在 io 包中最重要的是两个接口:Reader 和 Writer。
Reader 接口:
type Reader interface {
Read(p []byte) (n int, err error)
}Read 将 len(p) 个字节读取到 p 中。返回读取的字节数 n(0 <= n <= len(p))以及任何遇到的错误。即使 Read 返回的 n < len(p),也会在调用过程中使用 p 的全部作为暂存空间。若一些数据可用但不到 len(p) 个字节,Read 会照例返回可用的东西,而不是等待更多。
当 Read 在成功读取 n > 0 个字节后遇到一个错误或 EOF 情况,就会返回读取的字节数。它会从相同的调用中返回(非 nil 的)错误或从随后的调用中返回错误(和 n == 0)。无论如何,下一个 Read 都应当返回 0, EOF。调用者应当总在考虑到错误 err 前处理 n > 0 的字节。
Writer 接口:
type Writer interface {
Write(p []byte) (n int, err error)
}Write 将 len(p) 个字节从 p 中写入到基本数据流中。返回从 p 中被写入的字节数 n(0 <= n <= len(p))以及任何遇到的引起写入提前停止的错误。若 Write 返回的 n < len(p),就必须返回一个非 nil 的错误。Write 不能修改此切片的数据,即便它是临时的。
Seeker 接口:
type Seeker interface {
Seek(offset int64, whence int) (int64, error)
}Seeker 用来移动数据的读写指针。Seek 设置下一次读写操作的指针位置,每次的读写操作都是从指针位置开始的:
| whence 值 | 含义 |
|---|---|
| 0 | 表示从数据的开头开始移动指针 |
| 1 | 表示从数据的当前指针位置开始移动指针 |
| 2 | 表示从数据的尾部开始移动指针 |
offset 是指针移动的偏移量,返回移动后的指针位置和移动过程中遇到的任何错误。
ReaderFrom 接口:
type ReaderFrom interface {
ReadFrom(r Reader) (n int64, err error)
}ReadFrom 从 r 中读取数据到对象的数据流中,直到 r 返回 EOF 或 r 出现读取错误为止。返回值 n 是读取的字节数,返回值 err 就是 r 的返回值 err。
WriterTo 接口:
type WriterTo interface {
WriteTo(w Writer) (n int64, err error)
}WriterTo 将对象的数据流写入到 w 中,直到对象的数据流全部写入完毕或遇到写入错误为止。返回值 n 是写入的字节数,返回值 err 就是 w 的返回值 err。
ReaderAt 接口:
type ReaderAt interface {
ReadAt(p []byte, off int64) (n int, err error)
}ReadAt 从对象数据流的 off 处读出数据到 p 中,忽略数据的读写指针,从数据的起始位置偏移 off 处开始读取。在这点上 ReadAt 要比 Read 更严格。
WriterAt 接口:
type WriterAt interface {
WriteAt(p []byte, off int64) (n int, err error)
}WriteAt 将 p 中的数据写入到对象数据流的 off 处,忽略数据的读写指针,从数据的起始位置偏移 off 处开始写入。
文件读写
file 类在 os 包中的读写方法:
func (f *File) Read(b []byte) (n int, err error)
// Read方法从f中读取最多len(b)字节数据并写入b。它返回读取的字节数和可能遇到的任何错误。文件终止标志是读取0个字节且返回值err为io.EOF。
func (f *File) ReadAt(b []byte, off int64) (n int, err error)
// ReadAt从指定的位置(相对于文件开始位置)读取len(b)字节数据并写入b。它返回读取的字节数和可能遇到的任何错误。当n<len(b)时,本方法总是会返回错误;如果是因为到达文件结尾,返回值err会是io.EOF。
func (f *File) Write(b []byte) (n int, err error)
// Write向文件中写入len(b)字节数据。它返回写入的字节数和可能遇到的任何错误。如果返回值n!=len(b),本方法会返回一个非nil的错误。
func (f *File) WriteString(s string) (ret int, err error)
// WriteString类似Write,但接受一个字符串参数。
func (f *File) WriteAt(b []byte, off int64) (n int, err error)
// WriteAt在指定的位置(相对于文件开始位置)写入len(b)字节数据。它返回写入的字节数和可能遇到的任何错误。如果返回值n!=len(b),本方法会返回一个非nil的错误。
func (f *File) Seek(offset int64, whence int) (ret int64, err error)
// Seek设置下一次读/写的位置。offset为相对偏移量,而whence决定相对位置:0为相对文件开头,1为相对当前位置,2为相对文件结尾。它返回新的偏移量(相对开头)和可能的错误。
func (f *File) Sync() (err error)
// Sync递交文件的当前内容进行稳定的存储。一般来说,这表示将文件系统的最近写入的数据在内存中的拷贝刷新到硬盘中稳定保存。读取文件数据示例:
package main
import (
"os"
"fmt"
"io"
)
func main() {
/*
读取数据:
Reader接口:
Read(p []byte)(n int, error)
*/
// 读取本地aa.txt文件中的数据
// step1:打开文件
fileName := "/Users/ruby/Documents/pro/a/aa.txt"
file, err := os.Open(fileName)
if err != nil {
fmt.Println("err:", err)
return
}
// step3:关闭文件
defer file.Close()
// step2:读取数据
bs := make([]byte, 4, 4)
n := -1
for {
n, err = file.Read(bs)
if n == 0 || err == io.EOF {
fmt.Println("读取到了文件的末尾,结束读取操作。。")
break
}
fmt.Println(string(bs[:n]))
}
}写出数据到本地文件示例:
package main
import (
"os"
"fmt"
"log"
)
func main() {
/*
写出数据:
*/
fileName := "/Users/ruby/Documents/pro/a/ab.txt"
// step1:打开文件
// step2:写出数据
// step3:关闭文件
file, err := os.OpenFile(fileName, os.O_CREATE|os.O_WRONLY|os.O_APPEND, os.ModePerm)
if err != nil {
fmt.Println(err)
return
}
defer file.Close()
// 写出数据
bs := []byte{97, 98, 99, 100} // a,b,c,d
n, err := file.Write(bs[:2])
fmt.Println(n)
HandleErr(err)
file.WriteString("\n")
// 直接写出字符串
n, err = file.WriteString("HelloWorld")
fmt.Println(n)
HandleErr(err)
file.WriteString("\n")
n, err = file.Write([]byte("today"))
fmt.Println(n)
HandleErr(err)
}
func HandleErr(err error) {
if err != nil {
log.Fatal(err)
}
}文件复制
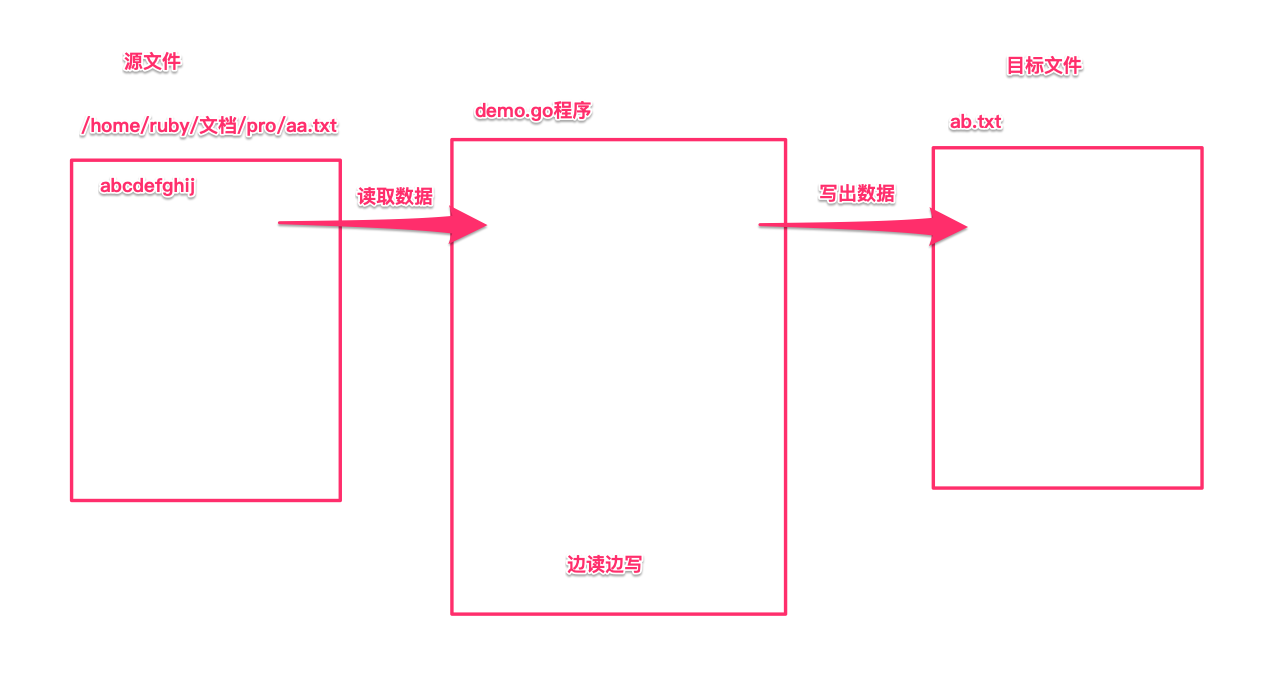
在 io 包中主要是操作流的一些方法,把文件从一个目录复制到另一个目录下,原理就是通过程序从源文件读取数据,再写出到目标文件里。
方法一:io 包下的 Read() 和 Write() 方法实现
通过 io 包下的 Read() 和 Write() 方法,边读边写,按块读取文件,块的大小也会影响到程序的性能。
/*
该函数的功能:实现文件的拷贝,返回值是拷贝的总数量(字节),错误
*/
func copyFile1(srcFile, destFile string) (int, error) {
file1, err := os.Open(srcFile)
if err != nil {
return 0, err
}
file2, err := os.OpenFile(destFile, os.O_WRONLY|os.O_CREATE, os.ModePerm)
if err != nil {
return 0, err
}
defer file1.Close()
defer file2.Close()
// 拷贝数据
bs := make([]byte, 1024, 1024)
n := -1 // 读取的数据量
total := 0
for {
n, err = file1.Read(bs)
if err == io.EOF || n == 0 {
fmt.Println("拷贝完毕。。")
break
} else if err != nil {
fmt.Println("报错了。。。")
return total, err
}
total += n
file2.Write(bs[:n])
}
return total, nil
}方法二:io 包下的 Copy() 方法实现
func copyFile2(srcFile, destFile string) (int64, error) {
file1, err := os.Open(srcFile)
if err != nil {
return 0, err
}
file2, err := os.OpenFile(destFile, os.O_WRONLY|os.O_CREATE, os.ModePerm)
if err != nil {
return 0, err
}
defer file1.Close()
defer file2.Close()
return io.Copy(file2, file1)
}扩展内容——io 包三个公开的 copy 方法:
Copy(dst, src):复制 src 全部到 dst 中。CopyN(dst, src, n):复制 src 中 n 个字节到 dst。CopyBuffer(dst, src, buf):指定一个 buf 缓存区,以这个大小完全复制。
无论是哪个 copy 方法最终都是由 copyBuffer() 这个私有方法实现的。复制主要分为 3 种情况:
- 如果被复制的 Reader(src)会尝试能否断言成 WriterTo,如果可以则直接调用 WriteTo 方法
- 如果 Writer(dst)会尝试能否断言成 ReadFrom,如果可以则直接调用 ReadFrom 方法
- 如果都没有实现,则调用底层 Read 实现复制
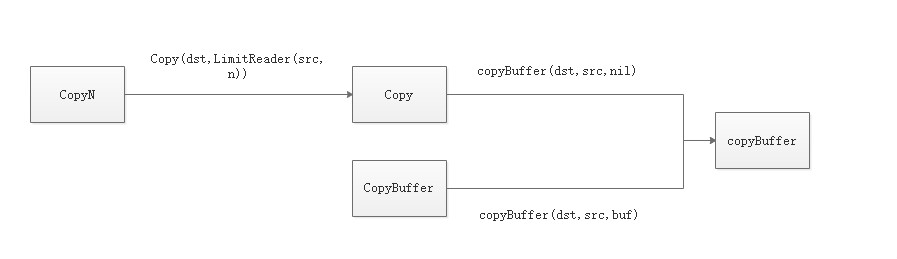
其中,Copy 和 CopyN 的区别是:如果 Copy,直接建立一个缓存区默认大小为 32 * 1024 的 buf;如果是 CopyN,会先判断要复制的字节数,如果小于默认大小,会创建一个等于要复制字节数的 buf。
方法三:ioutil 包
使用 ioutil.WriteFile() 和 ioutil.ReadFile() 实现,但由于使用一次性读取文件、再一次性写入文件的方式,该方法不适用于大文件,容易内存溢出。
func copyFile3(srcFile, destFile string) (int, error) {
input, err := ioutil.ReadFile(srcFile)
if err != nil {
fmt.Println(err)
return 0, err
}
err = ioutil.WriteFile(destFile, input, 0644)
if err != nil {
fmt.Println("操作失败:", destFile)
fmt.Println(err)
return 0, err
}
return len(input), nil
}三种拷贝方式性能测试: 拷贝一个 400M 的 mp4 文件,三种方式耗时对比如下:
bufio 包
Go 语言在 io 操作中,还提供了一个 bufio 的包,使用这个包可以大幅提高文件读写的效率。
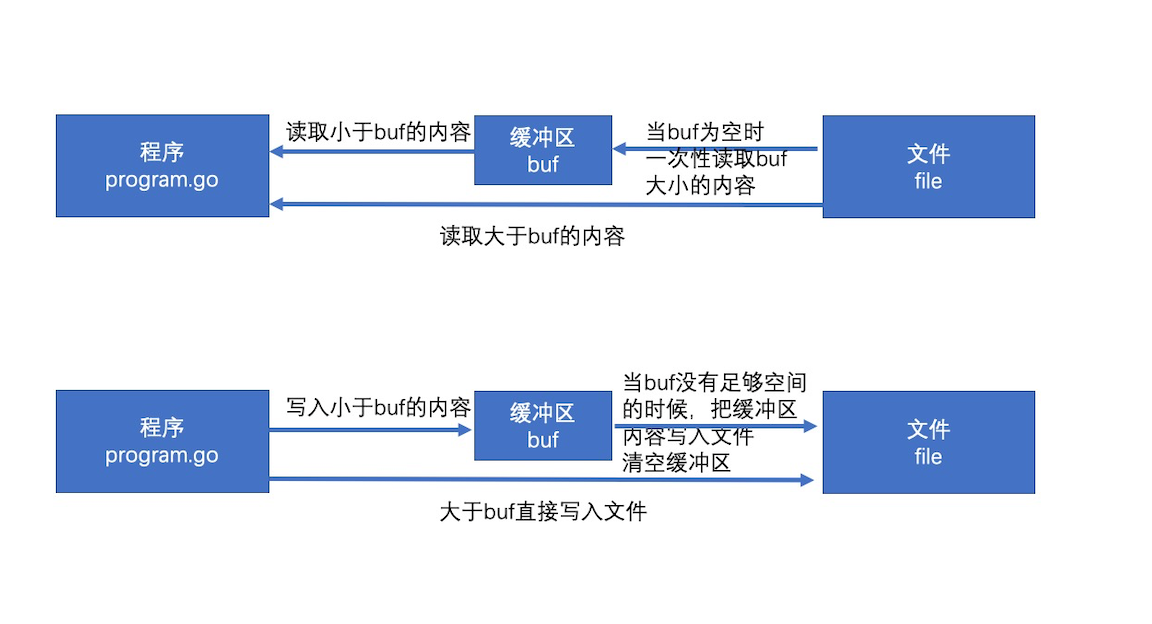
bufio 是通过缓冲来提高效率。io 操作本身的效率并不低,低的是频繁地访问本地磁盘的文件。bufio 提供了缓冲区(分配一块内存),读和写都先在缓冲区中进行,最后再读写文件,来降低访问本地磁盘的次数,从而提高效率。
bufio 封装了 io.Reader 或 io.Writer 接口对象,并创建另一个也实现了该接口的对象。
bufio.Reader:
// Reader implements buffering for an io.Reader object.
type Reader struct {
buf []byte
rd io.Reader // reader provided by the client
r, w int // buf read and write positions
err error
lastByte int // last byte read for UnreadByte; -1 means invalid
lastRuneSize int // size of last rune read for UnreadRune; -1 means invalid
}bufio.Read(p []byte) 的思路:
- 当缓存区有内容时,将缓存区内容全部填入 p 并清空缓存区
- 当缓存区没有内容且
len(p) > len(buf),即要读取的内容比缓存区还大,直接去文件读取 - 当缓存区没有内容且
len(p) < len(buf),即要读取的内容比缓存区小,缓存区从文件读取内容充满缓存区,并将 p 填满(此时缓存区有剩余内容) - 以后再次读取时缓存区有内容,将缓存区内容全部填入 p 并清空缓存区
Reader 内部通过维护一个 r、w 即读入和写入的位置索引来判断是否缓存区内容被全部读出。
bufio.Writer:
// Writer implements buffering for an io.Writer object.
type Writer struct {
err error
buf []byte
n int
wr io.Writer
}bufio.Write(p []byte) 的思路:
- 判断 buf 中可用容量是否可以放下 p
- 如果能放下,直接把 p 拼接到 buf 后面,即把内容放到缓冲区
- 如果缓冲区的可用容量不足以放下,且此时缓冲区是空的,直接把 p 写入文件
- 如果缓冲区的可用容量不足以放下,且此时缓冲区有内容,则用 p 把缓冲区填满,把缓冲区所有内容写入文件,并清空缓冲区
- 判断 p 的剩余内容大小能否放到缓冲区,如果能放下则把内容放到缓冲区
- 如果 p 的剩余内容依旧大于缓冲区(注意此时缓冲区是空的),则把 p 的剩余内容直接写入文件
当所有写入完成后,因为缓存区会存储内容,所以需要手动 Flush() 到文件。
bufio 包常用 API:
bufio.Reader 实现了 io.Reader、io.WriterTo、io.ByteScanner、io.RuneScanner 接口:
// NewReaderSize 将 rd 封装成一个带缓存的 bufio.Reader 对象,缓存大小由 size 指定(如果小于 16 则会被设置为 16)。
func NewReaderSize(rd io.Reader, size int) *Reader
// NewReader 相当于 NewReaderSize(rd, 4096)
func NewReader(rd io.Reader) *Reader
// Peek 返回缓存的一个切片,该切片引用缓存中前 n 个字节的数据,该操作不会将数据读出。
func (b *Reader) Peek(n int) ([]byte, error)
// Read 从 b 中读出数据到 p 中,返回读出的字节数和遇到的错误。
func (b *Reader) Read(p []byte) (n int, err error)
// Buffered 返回缓存中未读取的数据的长度。
func (b *Reader) Buffered() int
// ReadString 功能同 ReadBytes,只不过返回的是字符串。
func (b *Reader) ReadString(delim byte) (line string, err error)bufio.Writer 实现了 io.Writer、io.ReaderFrom、io.ByteWriter 接口:
// NewWriterSize 将 wr 封装成一个带缓存的 bufio.Writer 对象,缓存大小由 size 指定(如果小于 4096 则会被设置为 4096)。
func NewWriterSize(wr io.Writer, size int) *Writer
// NewWriter 相当于 NewWriterSize(wr, 4096)
func NewWriter(wr io.Writer) *Writer
// WriteString 功能同 Write,只不过写入的是字符串
func (b *Writer) WriteString(s string) (int, error)
// Flush 将缓存中的数据提交到底层的 io.Writer 中
func (b *Writer) Flush() error
// Available 返回缓存中未使用的空间的长度
func (b *Writer) Available() int
// Buffered 返回缓存中未提交的数据的长度
func (b *Writer) Buffered() int
// Reset 将 b 的底层 Writer 重新指定为 w,同时丢弃缓存中的所有数据。
func (b *Writer) Reset(w io.Writer)bufio 读取数据示例:
package main
import (
"os"
"fmt"
"bufio"
)
func main() {
/*
bufio:高效io读写
buffer缓存
io:input/output
将io包下的Reader,Write对象进行包装,带缓存的包装,提高读写的效率
ReadBytes()
ReadString()
ReadLine()
*/
fileName := "/Users/ruby/Documents/pro/a/english.txt"
file, err := os.Open(fileName)
if err != nil {
fmt.Println(err)
return
}
defer file.Close()
// 创建Reader对象
// b1 := bufio.NewReader(file)
// 1.Read(),高效读取
// p := make([]byte, 1024)
// n1, err := b1.Read(p)
// fmt.Println(n1)
// fmt.Println(string(p[:n1]))
// 2.ReadLine()
// data, flag, err := b1.ReadLine()
// fmt.Println(flag)
// fmt.Println(err)
// fmt.Println(data)
// fmt.Println(string(data))
// 3.ReadString()
// for {
// s1, err := b1.ReadString('\n')
// if err == io.EOF {
// fmt.Println("读取完毕。。")
// break
// }
// fmt.Println(s1)
// }
// 4.ReadBytes()
// data, err := b1.ReadBytes('\n')
// fmt.Println(err)
// fmt.Println(string(data))
// Scanner
b2 := bufio.NewReader(os.Stdin)
s2, _ := b2.ReadString('\n')
fmt.Println(s2)
}本地 english.txt 文件内容:
bufio 写入数据示例:
package main
import (
"os"
"fmt"
"bufio"
)
func main() {
/*
bufio:高效io读写
buffer缓存
io:input/output
将io包下的Reader,Write对象进行包装,带缓存的包装,提高读写的效率
func (b *Writer) Write(p []byte) (nn int, err error)
func (b *Writer) WriteByte(c byte) error
func (b *Writer) WriteRune(r rune) (size int, err error)
func (b *Writer) WriteString(s string) (int, error)
*/
fileName := "/Users/ruby/Documents/pro/a/cc.txt"
file, err := os.OpenFile(fileName, os.O_CREATE|os.O_WRONLY, os.ModePerm)
if err != nil {
fmt.Println(err)
return
}
defer file.Close()
w1 := bufio.NewWriter(file)
// n, err := w1.WriteString("helloworld")
// fmt.Println(err)
// fmt.Println(n)
// w1.Flush() // 刷新缓冲区
for i := 1; i <= 1000; i++ {
w1.WriteString(fmt.Sprintf("%d:hello", i))
}
w1.Flush()
}ioutil 包
除了 io 包可以读写数据,Go 语言中还提供了一个辅助的工具包就是 ioutil。
import "io/ioutil"ioutil 包的方法:
// Discard 是一个 io.Writer 接口,调用它的 Write 方法将不做任何事情并且始终成功返回。
var Discard io.Writer = devNull(0)
// ReadAll 读取 r 中的所有数据,返回读取的数据和遇到的错误。
// 如果读取成功,则 err 返回 nil,而不是 EOF,因为 ReadAll 定义为读取所有数据,所以不会把 EOF 当做错误处理。
func ReadAll(r io.Reader) ([]byte, error)
// ReadFile 读取文件中的所有数据,返回读取的数据和遇到的错误。
// 如果读取成功,则 err 返回 nil,而不是 EOF
func ReadFile(filename string) ([]byte, error)
// WriteFile 向文件中写入数据,写入前会清空文件。
// 如果文件不存在,则会以指定的权限创建该文件。返回遇到的错误。
func WriteFile(filename string, data []byte, perm os.FileMode) error
// ReadDir 读取指定目录中的所有目录和文件(不包括子目录)。
// 返回读取到的文件信息列表和遇到的错误,列表是经过排序的。
func ReadDir(dirname string) ([]os.FileInfo, error)
// NopCloser 将 r 包装为一个 ReadCloser 类型,但 Close 方法不做任何事情。
func NopCloser(r io.Reader) io.ReadCloser
// TempFile 在 dir 目录中创建一个以 prefix 为前缀的临时文件,并将其以读写模式打开。
func TempFile(dir, prefix string) (f *os.File, err error)
// TempDir 功能同 TempFile,只不过创建的是目录,返回目录的完整路径。
func TempDir(dir, prefix string) (name string, err error)ioutil 示例代码:
package main
import (
"io/ioutil"
"fmt"
"os"
)
func main() {
/*
ioutil包:
ReadFile()
WriteFile()
ReadDir()
..
*/
// 1.读取文件中的所有的数据
// fileName1 := "/Users/ruby/Documents/pro/a/aa.txt"
// data, err := ioutil.ReadFile(fileName1)
// fmt.Println(err)
// fmt.Println(string(data))
// 2.写出数据
// fileName2 := "/Users/ruby/Documents/pro/a/bbb.txt"
// s1 := "helloworld面朝大海春暖花开"
// err := ioutil.WriteFile(fileName2, []byte(s1), 0777)
// fmt.Println(err)
// 3.ReadAll
// s2 := "qwertyuiopsdfghjklzxcvbnm"
// r1 := strings.NewReader(s2)
// data, _ := ioutil.ReadAll(r1)
// fmt.Println(data)
// 4.ReadDir(),读取一个目录下的子内容:子文件和子目录,但是仅有一层
// dirName := "/Users/ruby/Documents/pro/a"
// fileInfos, _ := ioutil.ReadDir(dirName)
// fmt.Println(len(fileInfos))
// for i := 0; i < len(fileInfos); i++ {
// fmt.Println(i, fileInfos[i].Name(), fileInfos[i].IsDir())
// }
// 5.创建临时目录
dir, err := ioutil.TempDir("/Users/ruby/Documents/pro/a", "Test")
if err != nil {
fmt.Println(err)
}
defer os.Remove(dir) // 用完删除
fmt.Printf("%s\n", dir)
// 创建临时文件
f, err := ioutil.TempFile(dir, "Test")
if err != nil {
fmt.Println(err)
}
defer os.Remove(f.Name()) // 用完删除
fmt.Printf("%s\n", f.Name())
}遍历文件夹
可以使用 ioutil 包下的 ReadDir() 方法获取指定目录下的内容,返回文件和子目录。因为文件夹下还有子文件夹,而 ioutil 包的 ReadDir() 只能获取一层目录,所以需要使用递归来设计算法。
package main
import (
"io/ioutil"
"fmt"
"log"
)
func main() {
/**
遍历文件夹:
*/
dirname := "/Users/ruby/Documents/pro"
listFiles(dirname, 0)
}
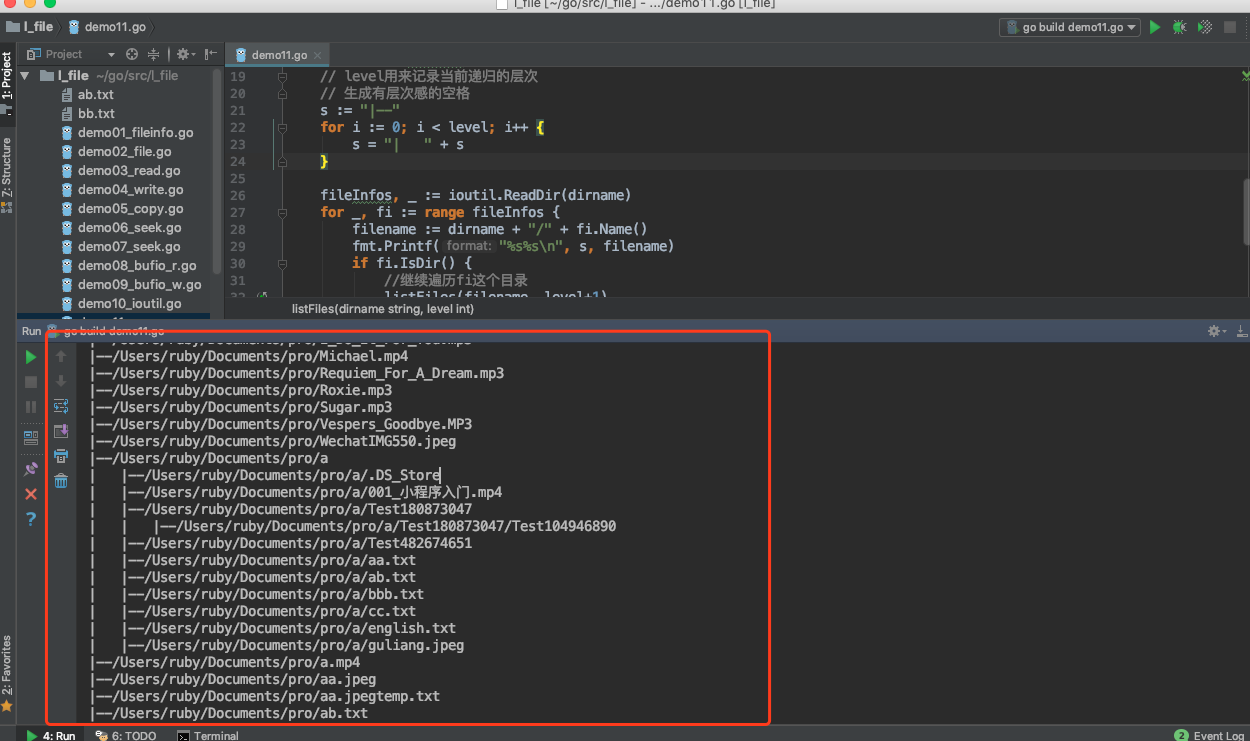
func listFiles(dirname string, level int) {
// level用来记录当前递归的层次
// 生成有层次感的空格
s := "|--"
for i := 0; i < level; i++ {
s = "| " + s
}
fileInfos, err := ioutil.ReadDir(dirname)
if err != nil {
log.Fatal(err)
}
for _, fi := range fileInfos {
filename := dirname + "/" + fi.Name()
fmt.Printf("%s%s\n", s, filename)
if fi.IsDir() {
// 继续遍历fi这个目录
listFiles(filename, level+1)
}
}
}
断点续传
Seeker 接口回顾:
type Seeker interface {
Seek(offset int64, whence int) (int64, error)
}Seek(offset, whence) 设置指针光标的位置,随机读写文件:
| whence 常量 | 值 | 含义 |
|---|---|---|
SeekStart | 0 | 相对于文件开始 |
SeekCurrent | 1 | 相对于当前偏移量 |
SeekEnd | 2 | 相对于结束 |
Seek 示例代码:
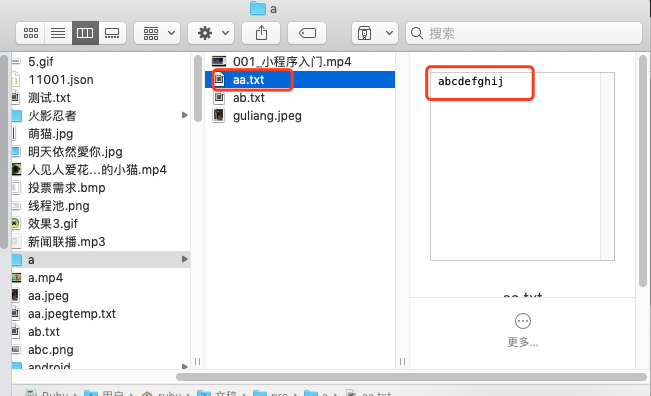
读取本地 aa.txt 文件,内容为
abcdefghij:
package main
import (
"os"
"fmt"
"io"
)
func main() {
/*
seek(offset,whence),设置指针光标的位置
第一个参数:偏移量
第二个参数:如何设置
0:seekStart表示相对于文件开始,
1:seekCurrent表示相对于当前偏移量,
2:seek end表示相对于结束。
随机读取文件:
可以设置指针光标的位置
*/
file, _ := os.OpenFile("/Users/ruby/Documents/pro/a/aa.txt", os.O_RDWR, 0)
defer file.Close()
bs := []byte{0}
file.Read(bs)
fmt.Println(string(bs))
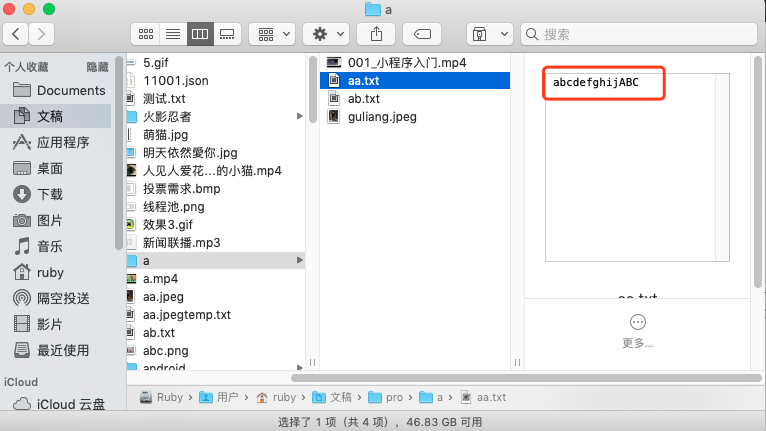
file.Seek(4, io.SeekStart)
file.Read(bs)
fmt.Println(string(bs))
file.Seek(2, 0) // 也是SeekStart
file.Read(bs)
fmt.Println(string(bs))
file.Seek(3, io.SeekCurrent)
file.Read(bs)
fmt.Println(string(bs))
file.Seek(0, io.SeekEnd)
file.WriteString("ABC")
}
断点续传实现:
想实现断点续传,主要就是记住上一次已经传递了多少数据。可以创建一个临时文件,记录已经传递的数据量,当恢复传递的时候,先从临时文件中读取上次已经传递的数据量,然后通过 Seek() 方法,设置到该读和该写的位置,再继续传递数据。
package main
import (
"fmt"
"os"
"strconv"
"io"
)
func main() {
/*
断点续传:
文件传递:文件复制
/Users/ruby/Documents/pro/a/guliang.jpeg
复制到
guliang4.jpeg
思路:
边复制,边记录复制的总量
*/
srcFile := "/Users/ruby/Documents/pro/a/guliang.jpeg"
destFile := "guliang4.jpeg"
tempFile := destFile + "temp.txt"
// fmt.Println(tempFile)
file1, _ := os.Open(srcFile)
file2, _ := os.OpenFile(destFile, os.O_CREATE|os.O_WRONLY, os.ModePerm)
file3, _ := os.OpenFile(tempFile, os.O_CREATE|os.O_RDWR, os.ModePerm)
defer file1.Close()
defer file2.Close()
// 1.读取临时文件中的数据,根据seek
file3.Seek(0, io.SeekStart)
bs := make([]byte, 100, 100)
n1, err := file3.Read(bs)
fmt.Println(n1)
countStr := string(bs[:n1])
fmt.Println(countStr)
// count, _ := strconv.Atoi(countStr)
count, _ := strconv.ParseInt(countStr, 10, 64)
fmt.Println(count)
// 2. 设置读,写的偏移量
file1.Seek(count, 0)
file2.Seek(count, 0)
data := make([]byte, 1024, 1024)
n2 := -1 // 读取的数据量
n3 := -1 // 写出的数据量
total := int(count) // 读取的总量
for {
// 3.读取数据
n2, err = file1.Read(data)
if err == io.EOF {
fmt.Println("文件复制完毕。。")
file3.Close()
os.Remove(tempFile)
break
}
// 将数据写入到目标文件
n3, _ = file2.Write(data[:n2])
total += n3
// 将复制总量,存储到临时文件中
file3.Seek(0, io.SeekStart)
file3.WriteString(strconv.Itoa(total))
// 假装断电
// if total > 8000 {
// panic("假装断电了。。。,假装的。。。")
// }
}
}